
ReGeneration Learning of Diffusion Models with Rich Prompts for Zero-Shot Image Translation
Yupei Lin $^{1}$, Sen Zhang $^2$, Xiaojun Yang $^1$, Xiao Wang $^3$, Yukai Shi $^{1*}$
${}^1$ Guangdong University of Technology, ${}^2$ The University of Sydney, ${ }^3$ Anhui University

Abstract
Large-scale text-to-image models have demonstrated amazing ability to synthesize diverse and high-fidelity images. However, these models are often violated by several limitations. Firstly, they require the user to provide precise and contextually relevant descriptions for the desired image modifications. Secondly, current models can impose significant changes to the original image content during the editing process. In this paper, we explore ReGeneration learning in an image-to-image Diffusion model (ReDiffuser), that preserves the content of the original image without human prompting and the requisite editing direction is automatically discovered within the text embedding space. To ensure consistent preservation of the shape during image editing, we propose cross-attention guidance based on regeneration learning. This novel approach allows for enhanced expression of the target domain features, while preserving the original shape of the image. In addition, we introduce a cooperative update strategy, which allows for efficient preservation of the original shape of an image, thereby improving the quality and consistency of shape preservation throughout the editing process. Our proposed method leverages an existing pre-trained text-image diffusion model without any additional training. Extensive experiments show that the proposed method outperforms existing work in both real and synthetic image editing.
Pipeline

Dataset
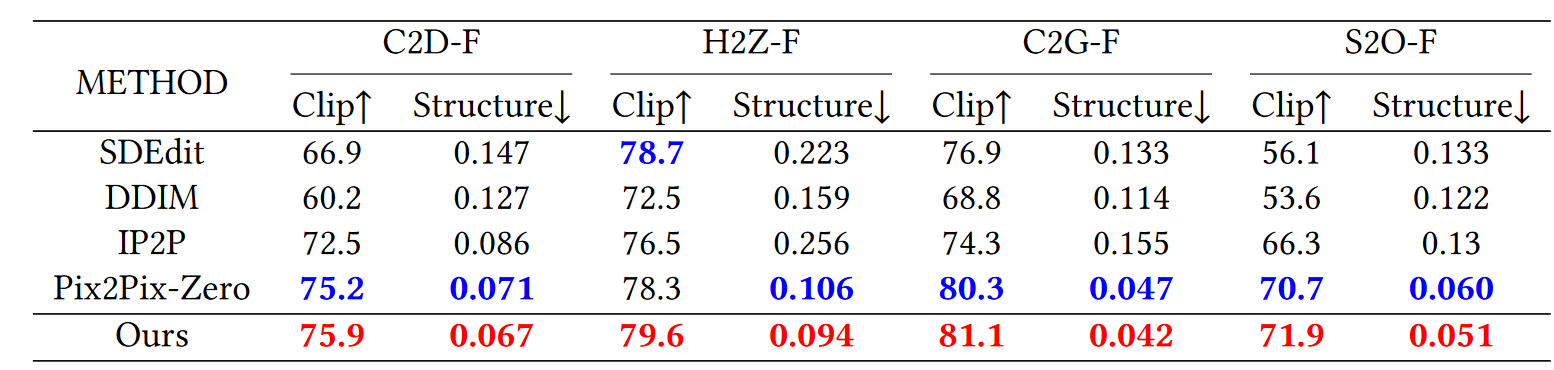
- Cat(C2D-F and C2G-F): Google drive
- Horse(H2Z-F): Google drive
- Sketch(S2O-F): Google drive
Generated Results

Qualitative Results
Additional results
Cat to Dog-Free

Horse to Zebra-Free

Cat Add Glasses

Sketch to Oil-Free
